Souvent, nous sommes confrontés à des architectures comportant un environnement de production et un ou plusieurs environnements de tests tentant tant bien que mal de reproduire l’environnement de production. Les mises en productions dans de tels environnements sont souvent synonymes de stress. Il est si facile d’oublier de mettre à jour une des composantes ou encore d’omettre un changement de configuration. Ce sont là deux problèmes faciles à corriger. Le pire survient lorsqu’une fois les composantes déployées on réalise que la nouvelle version ne fonctionne pas bien. Évidemment, ces test qui tentent de reproduire la réalité ne sont pas fidèles et peuvent être blâmés, mais le mal est fait.
Quels sont les problèmes de cette approche?
- Les tests sont incomplets car simuler un environnement de production est hyper complexe et demande beaucoup de temps. Et si on se servait de la production elle-même plutôt que d’une simulation?
- Le déploiement en soi comporte un risque. Et si on ne déployait pas?

À fin d’exemple, considérons un système fermé de traitement de données. À chaque jour, un client dépose des données sur le serveur de production. celui-ci les traite, crée un fichier de résultats puis retourne celui-ci au client. Le serveur de test, de son côté, détecte que le fichier du client a été déposé sur le serveur de production, le télécharge localement, le traite puis produit des résultats. Il est donc facile pour nous de les comparer.
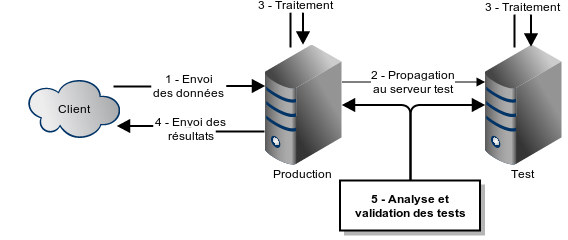
Néanmoins, nous ne testons pas vraiment en production. Pour ce faire, il faudrait que les 2 machines agissent de façon identique. Ici, les différences de la machine de test sont qu’elle doit télécharger les données entrantes à partir de la machine de production et que contrairement à celle-ci elle ne fait rien avec les résultats. Pour rendre les 2 processus identiques, il faudrait que le client dépose le fichier d’entrée dans un endroit neutre (ex.: un 3è serveur, un « bucket » amazon s3) et que les machines soient configurées pour y prendre leurs données entrantes. Pour la sortie, les machines ne pourraient toutefois pas téléverser leurs résultats avec la même approche car l’une écraserait les résultats de l’autre ce qui d’une part ne garanti pas que nous gardons bien le fichier de production et de l’autre nous empêche de comparer les résultats. Il faut donc qu’elles gardent les résultats localement et qu’un processus externe viennent les chercher. Une 3è machine peut prendre les résultats de la production et les envoyer au client ou celui-ci peut carrément récupérer les résultats lui-même. Ainsi, nous avons une machine de production et une machine de tests qui ont un fonctionnement identique du point de vue externe.
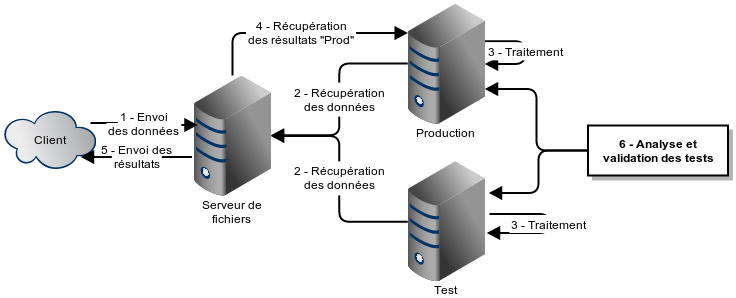
Vient le temps de faire la mise à jour de l’environnement de production. Nous sommes certains que la version de tests est fonctionnelle puisqu’elle a tourné avec succès depuis X jours. Pourquoi prendrions-nous le risque de mettre à jour l’environnement de production et possiblement louper une configuration quelconque et ainsi compromettre le système alors que nous avons déjà un environnement qui correspond exactement à ce que nous désirons avoir en production? En clair, pourquoi ne pas simplement définir l’environnement de tests comme le nouvel environnement de production et vice versa? L’ancienne machine de production devient la nouvelle machine de tests et c’est là que le développement et les tests de la prochaine itération prendront place. Comment faire? Il suffit d’alterner les configurations du réseau. Il y a plusieurs options possibles; sur linux on peut modifier le fichier /etc/hosts du serveur de fichier, si le réseau dispose de son propre DNS on peut y changer la configuration ou encore sur Amazon S3 on peut réassigner les IP statiques. Reprenons avec notre exemple. Le client s’attend à trouver les résultats sur le serveur de fichiers. C’est donc ce dernier qui doit télécharger les résultats de la production. Celui-ci interroge comme toujours le DNS pour avoir l’adresse du serveur « prod.macompagnie.net » et le DNS qui vient d’être reconfiguré retourne l’adresse du nouveau serveur de production. Voilà, le tour est joué.
Ainsi, nous avons effectué des « tests en production » et avons « déployé sans déployer ».
Cette approche reste fonctionnelle si le client a besoin d’un changement de comportement visible au monde extérieur. (Ex.: changement du format des résultats.) Celui-ci devra aussi tester son système. Il pourra le faire pointer directement sur notre serveur de tests. Puis, lorsque les 2 parties en conviendront, il faudra redésigner leur serveur de production et de tests.
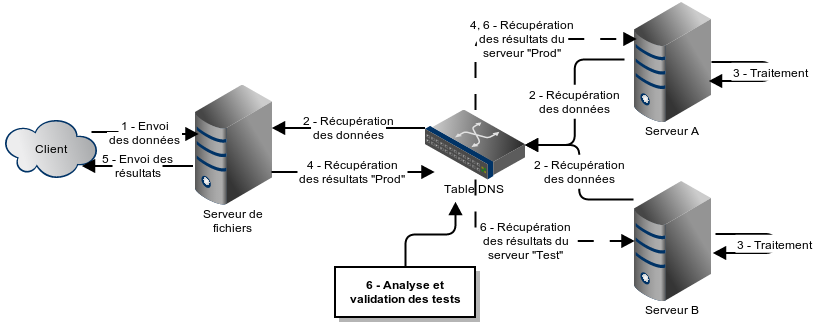
Cette approche ne peut pas s’appliquer aussi facilement à tous les systèmes. Avec un peu de travail nous pouvons toutefois y arriver souvent avec l’ajout d’un système de dédoublement. Par exemple, supposons un service REST. L’appel envoyé au serveur X n’atteindra jamais le serveur Y seul. Pour régler le problème, il faut ajouter un serveur S en amont qui recevra les commandes et les enverra à X et Y, recevra la réponse de chacun d’entre-eux et ne retournera que la réponse du serveur désigné comme production. Pour fin de validation, toute disparité entre les 2 réponses devrait être journalisée. (Et on souhaite probablement ajouter un temps d’attente limite sur le serveur de tests au cas où il ne répondrait pas du tout.)
Évidemment, l’ajout d’un serveur en amont et de comparaison des résultats peut ne pas être acceptable. Par exemple, sur un système fonctionnant en temps réel, l’ajout d’un serveur de dédoublement en amont peut causer un délai inacceptable. Par ailleurs, un tel système ne remplacera jamais toutes les formes de tests. (ex.: Tests de charge, tests de vulnérabilité). Les cas limites ayant une faible occurrence en production ne seront possiblement pas testés non plus.
Cette technique élimine une grande partie des soucis associés aux déploiements traditionnels. Bien qu’elle peut permettre d’éliminer certains aspects des tests (tout ce qui se produit sur une base régulière en production n’a plus besoin d’être testé séparément), elle ne doit pas être vue comme une technique de remplacement mais un complément.
Intéressant, ça semble une technique très efficace pour votre situation. J’ai de la misère à imaginer comment l’appliquer dans un environnement avec des bases de données qui doivent être modifiées.
Par exemple si je déploie en test/staging et que je modifie la base de données, je peux pas partager ces données et quand un utilisateur apporte des modifications en production, je ne peux pas toujours faire les mêmes modifications en parallèle en test/staging. Mais bon, j’ai quand même un setup similaire, je déploie en staging, je test et quand je suis confiant je fais le même déploiement en production, ça fonctionne assez bien.
Bon point pour « ne doit pas être vue comme une technique de remplacement mais un complément », c’est très important.
Salut @Michel!
Merci pour ton message! Je spécule, mais je pense que dans le cas d’une base de données il doit être possible d’installer un proxy en face de deux bases de données qui effectue les appels dans les deux systèmes. Dans tous les cas, l’architecture dont je parle a ses limites.