
Character encoding. That and date time formats are what I consider the two biggest wastes of programmer time when handling data. For the later, sticking to iso-8601 rules out the problem. (Read my Timestamps post for more information.) For the former, sticking to ASCII or UTF8 should work all the time. However, just like for timestamps, you may not control the source and get some “unfriendly” formats. Here are my tips to detect them.
Here are three basic files.
- ascii.txt, encoded in ASCII
- utf8.txt, encoded in UTF-8
- unknown.txt, encoded in… a non friendly format!
The first thing to do if you have access to a bash shell is see if it can detect it for you.
%>file ascii.txt ascii.txt: ASCII text %>file utf8.txt utf8.txt: UTF-8 Unicode text %>file unknown.txt unknown.txt: Non-ISO extended-ASCII text, with CRLF line terminators %> cat unknown.txt TypeDeP�riode
For the first two files, it worked. For the last one, it did not. In only tells us that it is not ISO extended-ASCII text. Plus, the “cat” command output shows an unknown character.
Sticking to the console, you can try a more advanced detection tool like python chardet.
%>chardet ascii.txt utf8.txt unknown.txt ascii.txt: ascii with confidence 1.0 utf8.txt: TIS-620 with confidence 0.99 unknown.txt: windows-1252 with confidence 0.5
This one detects the two firsts encodings easily (confidence 1 and 0.99) but is very uncertain about the last one (confidence 0.5). Testing it in ipython shows that it is wrong.
In [1]: import codecs
In [2]: f = codecs.open('unknown.txt', 'rt', encoding='windows-1252')
In [3]: print f.readline()
TypeDeP‚riode
It did not work. Had it worked, «TypeDePériode» would have been printed.
My last resort is using a text editor and trying all encodings that make sense until you find the right one. On windows, I think notepad++ is great for that. Another “tool” that can also be used is Libre Office calc. Open it and then load your file via the menu “File” > “Open…”. The “import text” dialog will be displayed.
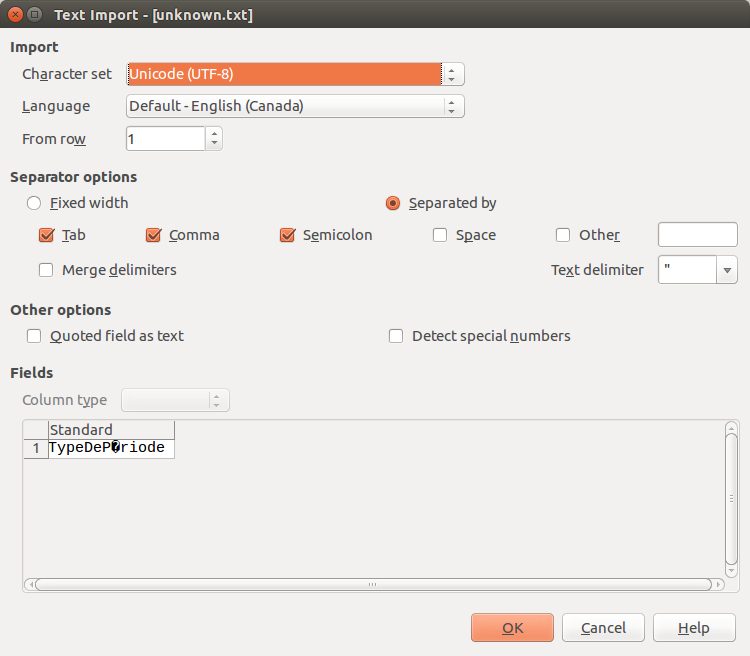
If your file is a CSV, it will split it accordingly. If it’s a text file, it should put everything in the first cell. Either way, it will work.
Notice here that what is supposed to be an «é» character is displayed as the UTF-8 undisplayable character. Use the “character set” option to scroll through the choices until your text looks good.
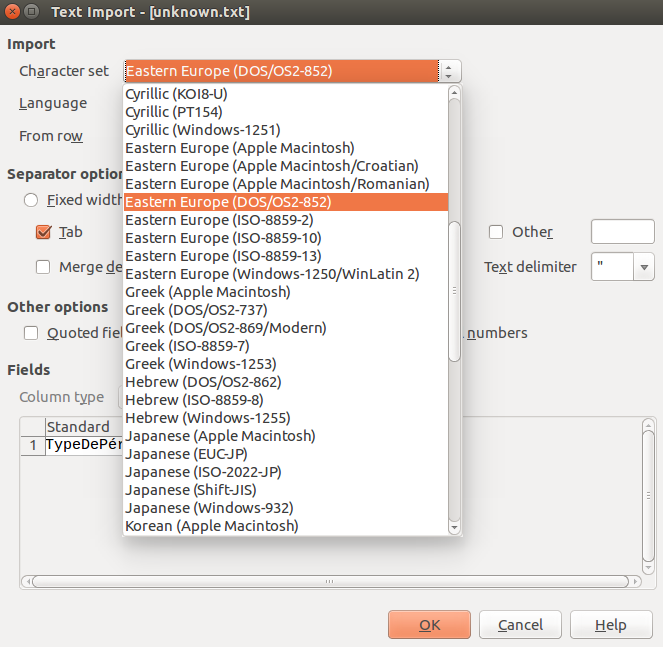 We can now see that our character «é» is mapped properly. We found the character encoding to be DOS/OS2-852. The easiest thing to do now is to convert it to a friendlier format. (UTF-8!) Still using Libre Office calc, open a new spreadsheet and copy paste all of your content from the old to the new one. Then hit the menu “File” > “Save As…”. Enter a file name and end it by “.csv”. Hit “Save”. If you haven’t done this kind of operation before, you should get a prompt about saving in either odf or CSV text format. Choose the later. You will get another prompt where you get to select encoding. Select utf-8. Et voilà. You have successfully converted your file. If your original file was not a csv, you can simply rename your new file to remove the “.csv” extension and replace it with “.txt”. Now, looking back at our terminal:
We can now see that our character «é» is mapped properly. We found the character encoding to be DOS/OS2-852. The easiest thing to do now is to convert it to a friendlier format. (UTF-8!) Still using Libre Office calc, open a new spreadsheet and copy paste all of your content from the old to the new one. Then hit the menu “File” > “Save As…”. Enter a file name and end it by “.csv”. Hit “Save”. If you haven’t done this kind of operation before, you should get a prompt about saving in either odf or CSV text format. Choose the later. You will get another prompt where you get to select encoding. Select utf-8. Et voilà. You have successfully converted your file. If your original file was not a csv, you can simply rename your new file to remove the “.csv” extension and replace it with “.txt”. Now, looking back at our terminal:
%>mv unknownFixed.csv unknownFixed.txt %>file unknownFixed.txt unknownFixed.txt: UTF-8 Unicode text %> cat unknownFixed.txt TypeDePériode
As you can see, the file type is now right and the “cat” command output is clean.
If you don’t like converting the file, there is another way. Had it been most of other formats, it would have been straight forward. But Open Office “DOS/OS2-852” doesn’t seem to map to anything known by that name so I had to search the web to finally find out that it is “cp437“, a DOS format. Going back into ipython we can try it.
In [4]: f = codecs.open('unknown.txt', 'rt', encoding='cp437')
In [5]: print f.readline() # It is important to actually use print
TypeDePériode
In [6]: f.seek(0)
In [7]: f.readline() # Without print it still looks as it's not working
Out[8]: u'TypeDeP\xe9riode\r\n'
My closing line: you cannot control the type of files you get, but you certainly control the type of files you produce. For text, unless you hate your users, please stick to UTF-8 or ASCII. Thank you.
Bonus picture.

…The bonus pic? That is absolutely genius. 🙂